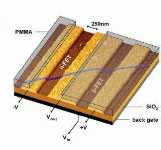
Полезные хитрости АЛУ, блок декодировки и управления — это еще не весь процессор. Оставь инженеры все как есть, он, может, и работал бы, но не так шустро, как мы хотим. Поэтому инженеры добавили к базовой архитектуре процессора несколько хитростей, без которых наша виртуальная жизнь много потеряла бы в красоте и разнообразии. Это конвейеры, кэш-память, блок вычислений с плавающей точкой, блоки дополнительных инструкций MMX или 3DNow!, а также несколько продвинутых приемов работы с данными. Давайте рассмотрим все это богатство по порядку. Если вы внимательно читали предыдущую статью, то наверняка заметили, что все операции, которые выполняет процессор, можно условно поделить на несколько стадий. Это стадии выборки, декодирования, определения адреса, выполнения и сохранения. Представляете, что будет, если все эти операции взвалить на один блок? На самом же деле разные операции выполняют разные блоки процессора, только для этого и предназначенные. Представим себе такую ситуацию. Команда поступила в блок предварительной выборки, который переслал ее в декодировщик. Декодировщик послал остальным цепям процессора определенные указания по исполнению команды. Блок управления следил за очередностью исполнения операций. А что в это время делали блоки предварительной выборки и декодировки? Да ничего, стояли в сторонке и курили. Что, конечно же, не есть хорошо. В ЦПУ, где каждый мегагерц на счету, все участники процесса должны работать на полную катушку. Почему бы блоку предварительной выборки не заняться следующей командой, после того как он отправил предыдущую в блок декодировки? Почему бы блоку декодировки не принять следующую команду от блока предварительной выборки сразу после выполнения предыдущей, не дожидаясь конца всего цикла обработки команды? То есть процессор как бы будет выполнять несколько команд одновременно. Вам эта процедура, кстати, ничего не напоминает? Конечно же — стандартная
схема организации конвейерного производства! Применяем ее к процессору — и получаем теоретический прирост производительности от 20 до 50%. А если при этом в процессоре будет не один конвейер, а несколько? Для справки — ЦПУ, имеющий более двух конвейеров c более чем пятью этапами в каждом, называется "суперскалярным" или "суперконвейерным". Однако не все так просто в королевстве датском. Этапы выполнения команд в каждом из блоков не одинаковы по времени. Может случиться так, что последующая инструкция выполнится быстрее, чем предыдущая в параллельном конвейере. Это нарушит очередность выполнения команд. Выполнение очередной команды может также зависеть от результата предыдущей. Соответствующему блоку придется некоторое время простаивать, ожидая выполнения нужной команды на другом этапе. Первая напасть решается довольно просто: вводится некоторое число промежуточных буферов, которые сохраняют результаты работы конфликтующих во времени команд. Вторая напасть решается более изощренно. Чтобы устранить простои блоков процессора, используются переименование регистров, одновременное использование данных в обоих конвейерах и сохранение промежуточных значений в специальных буферах. В процессорах посовременнее применяются и вовсе "шаманские" приемы. Например, при условном переходе простои неизбежны, ведь блокам конвейера приходится дожидаться адреса перехода. А зачем ждать? Может, лучше попытаться "угадать" адрес перехода, основываясь на предыдущих переходах? Все переходы, встречающиеся в программе, процессор запоминает в специальном буфере (branch target buffer). И на основе данных из этого буфера делается предсказание, будет ли произведен переход, а если будет, то куда. Если процессор ошибся и "послал" выполнение программы не туда, куда надо, приходится возвращаться к предыдущему шагу (что отнимает массу времени). Все это похоже на гадания на кофейной гуще, однако современные процессоры предсказывают адрес перехода с точностью до 90%, и потери производительности при ошибках практически незаметны. Кэш — это специальный участок памяти, работающий на частоте, равной частоте процессора или вдвое меньше ее. Кэш-память работает гораздо быстрее оперативной и имеет очень высокую себестоимость. В ней хранятся команды и данные, с которыми процессор работает в данный момент. У некоторых процессоров кэш данных и кэш инструкций разделены, у других они единое целое. Второй вариант предпочтительнее, потому что процессор может гибко изменять соотношение количества памяти, выделяемого под хранение данных и инструкций. Благодаря кэшу производительность процессора увеличивается. Во многих процессорах имеется несколько уровней кэш-памяти. В "домашних" процессорах их, как правило, два, в серверных, как правило, три. Эти уровни могут различаться по скорости и по объему. Как правило, кэш L1 (level 1) — кэш первого уровня, самый маленький и самый быстрый. FPU, он же Floating Point Unit, он же блок операций с плавающей точкой — неотъемлемая часть современных процессоров. От его скорости, в конечном счете, зависит производительность процессора в компьютерных играх. С блоком FPU косвенно связан и блок расширенных операций — в некоторых процессорах это MMX, в других — 3DNow! или SSE. Он отвечает за выполнение дополнительных инструкций, предназначенных для обработки графики, видео и звука. Фактически эти инструкции представляют собой набор дополнительных регистров расширенной разрядности (128 бит в реализации SSE) и набора операций над ними. Супербизон В условиях, когда надо перемалывать тонны информации за пару секунд, когда конкуренты наступают на пятки, когда цена упущенной минуте — подзатыльник провинившемуся сотруднику (ценная идея! — от ред.), когда от скорости зависит все, невозможно обойтись без суперкомпьютеров. Они управляют спутниками, обрабатывают котировки ценных бумаг, рассчитывают сложнейшие электронные схемы (воссоздают себе подобных) и делают еще массу полезностей. Суперкомпьютеру — суперпроцессор! Так звучал бы лозунг советских времен на каком-нибудь заводе высоких технологий. Но в реальной жизни лозунг этот не пройдет. Со всей прямотой и ответственностью заявляю: нет никаких суперпроцессоров! Конечно же, имеются отдельные экзотические экземпляры в прототипах, в отдельных малопопулярных системах, на бумаге, но ни в одном суперкомбайне от IBM или Sun вы не встретите подобных монстров. Да и зачем они нужны? Греться будут, как все цеха Урюпинского Сталелитейного, а толку ноль. Не проще, не дешевле ли объединить несколько десятков, сотен, тысяч обычных процессоров и заставить их работать в связке? Ответ — "безусловно". Собственно, все суперкомпьютеры так и устроены. К сожалению, если заменить один процессор двумя, то вместе они не будут работать в два раза быстрее. И тысяча процессоров не будут работать в десять раз быстрее, чем сто. Это и есть основная проблема масштабирования многопроцессорных систем. Как распределить умножение двух простых чисел между двумя процессорами? А никак. Поэтому и программистам, и инженерам приходится подходить к делу творчески. Абы какая программа не сможет работать на многопроцессорном суперкомпьютере так же хорошо, как и на обычном. Поэтому программисты затачивают программы под число процессоров, заставляют процессоры эффективнее трудиться в общей упряжке. Неплохо продвинулись в освоении многопроцессорной нивы и отечественные спецы. Например, еще в 1993 году фирма "Мультикон" совместно с белорусским заводом "Интеграл" выпустила суперкомпьютер, состоящий из 4600 процессоров! Сейчас в России суперкомпьютерами занимается фирма "Суперкомпьютерные системы" в рамках проекта СКИФ и при поддержке Института программных систем Российской Академии Наук. Они хотят реализовать фантастический проект — персональный суперкомпьютер, который будет доступен по цене для домашнего использования! При этом его производительность сможет тягаться с производительностью нескольких десятков четвертых Пентиумов вместе взятых. На грани возможного В последнее время компьютерные технологии развиваются
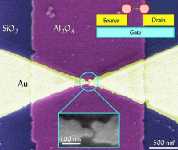
Транзистор из одного атома. достаточно равномерно, демонстрируя постоянный, и оттого ужасно предсказуемый и скучный эволюционный процесс. Автору же, как, надеюсь, и многим нашим читателям, до колик в желудке хочется маленькой, но стремительной и эффектной революции! Судите сами: последние три-четыре года производители процессоров только и делали, что увеличивали гигагерцы и уменьшали технологический процесс. Скоро они перейдут на 0.09 технологию, потом уменьшат транзисторы еще раз, и еще, и еще разок. До некоего предела, который, само собой, имеется и у современных технологий производства процессоров. Финиш будет достигнут уже в ближайшее десятилетие. Законный вопрос — а что потом? Им, что неудивительно, уже давно задаются ученые умы ведущих компаний мира. К примеру, IBM пытается внедрить интегральную логику на основе углеродных нанотрубок. Транзисторы на нанотрубках в несколько раз быстрее своих кремниевых аналогов. Элементарный рабочий прототип спецы из IBM разработали еще в прошлом году, и на данный момент работают над его доводкой. Пытаются сделать нанотранзистор надежным и высокопроизводительным. По предварительным оценкам логика на углеродных нанотрубках обещает стать достойной заменой кремнию и, вероятно, именно она обеспечит регулярный прирост производительности процессоров еще на несколько лет. Но и эта технология рано или поздно исчерпает себя. Поэтому ученые уже сейчас ищут еще более радикальные решения проблемы. И если вы ищете ответ на вопрос, какие процессоры будут стоять в ваших системных блоках через десять лет, то у меня будет для вас всего два варианта ответа. Будущее за
Нанокапсулы, введенные в кровь, перемещаются по организму человека в поисках больных клеток. (Иллюстрация NASA) био- и нанотехнологиями. Если прогресс свернет на дорожку биотехнологий, очень скоро мы получим компьютеры, вживляемые под кожу, в сетчатку глаза и, прости господи, прямо в мозг. Процессоры будут состоять из органических элементов, и как вариант — из тканей человека. Работы в этом направлении ведутся уже чуть ли не полвека. Ученые всерьез надеются создать высокоскоростные компьютеры на базе ДНК. Двое китайских гениев уже создали миниатюрный двигатель всего из одной молекулы ДНК. Есть надежда, что через несколько лет мы получим биочипы, в которых микроэлектромеханические технологии удачно сочетаются с биологическими процессами. Кстати, компания Bowei BioTech уже использует подобные ДНК-биочипы в приложениях, связанных с безопасностью. Биозонды, которые, курсируя в крови человека, будут лечить пораженные органы на микроуровне, — дело недалекого будущего. А там рукой подать и до процессоров, построенных преимущественно с помощью биотехнологий. Многие ученые считают, что компьютеры на ДНК — это половинчатое решение. Раз решили уменьшать и убыстрять компьютеры — надо идти до конца. Даешь компьютеры на молекулах и даже на атомах! Это не фантастика. Фактически — технология ближайших нескольких лет. В институте Bell Labs изобрели молекулярный транзистор еще в 1947 году, а буквально недавно там же научились соединять транзисторы между собой. На рынке нанотехнологий по этому поводу очень скоро должна разразиться настоящая война. Ибо такие гиганты, как Intel, IBM и HP, стремятся как можно скорее застолбить себе место на перспективном рынке. В HP недавно решили проблему, которая стояла на пути создания полноценных интегральных схем на молекулярном уровне. Раньше они предлагали использовать простейшую сеть из проводников толщиной всего в несколько атомов, соединенных одномолекулярными триггерами. Незадача этого решения заключается в том, что электрические сигналы в таких схемах влияют друг на друга, и логика их работы нарушается. HP смогли победить неприятность простой и элегантной резолюцией, преобразовав некоторые узлы сети в изоляторы с помощью проводников, химическая структура которых отличается от остальной сети. Если так пойдет и дальше, то, глядишь, лет через пятнадцать на конвейер поступят первые атомарные компьютеры... Вот только интересно, а куда ученые будут двигаться после атомов? Что еще придумают? Может, научатся управлять отдельными электронами? Поживем — увидим.
1206 Прочтений • [История микропроцессора, часть 3. За далью даль] [19.05.2012] [Комментариев: 0]











 Vova
Vova