Microsoft Pivot: новое в визуализации веб-контента
Microsoft Pivot: новое в визуализации веб-контента
Новый проект Microsoft Labs выглядит многообещающе. Если его удастся протолкнуть в большой мир, то он навсегда изменит представление об удобных способах работы с информационными сайтами. Например, с Wikipedia.
Автор: Игорь Терехов
| Раздел: Статьи |
Дата: 04 декабря 2009 года
Во второй половине ноября Microsoft Labs представила свою новую разработку - Pivot. Вчера я наконец-то получил регистрационный код и смог проиграться с ней самостоятельно, а не довольствоваться скупой видеопрезентацией. В конце статьи вы сможете найти этот код - его можно использовать ещё девять раз, поэтому если вы зашли сюда одним из первых, то вам несказанно повезло.
Штука от Microsoft получилась настолько необычная и в то же время простая, что коротко описать её довольно трудно. По сути Pivot - это инструмент для удобной работы с большими базами данных, каждый элемент которых может быть представлен в виде изображения. Самый простой пример: база данных пород собак. Каждая порода может быть проиллюстрирована, она также имеет множество атрибутов, по которым можно проводить отбор и сортировку. На коротком видео ниже, снятом на какой-то конференции, показана реализация этой идеи в Pivot.
Как вы видите, пользоваться Pivot довольно просто. В его основе лежат так называемые коллекции, которые объединяют большие группы похожих элементов. В идеале это может означать, что через некоторое время на сайтах, предоставляющих пользователю большой объём информации (например, на "Компьютерре-Онлайн") может появиться кнопочка “Get in Pivot” и тогда наши читатели смогут легко перемещаться по архиву статей, используя ключевые слова, видеть все связанные материалы и больше не жаловаться на плохо работающий традиционный поиск.
Другой понятный пример использования - база данных "Яндекс.Маркет". Отбирать товары, наблюдая за красиво визуализированными процессами поиска и сравнения товаров, было бы намного удобнее и приятнее, чем сейчас.
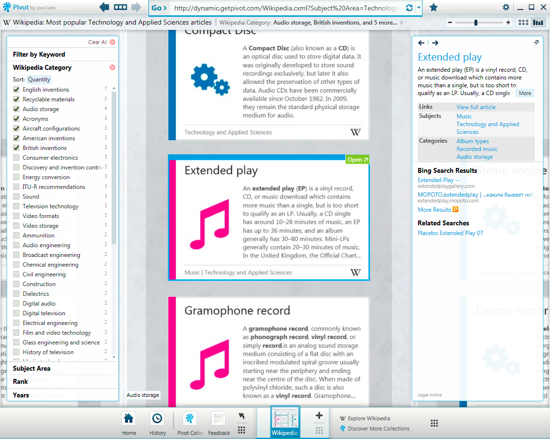
Нечто подобное уже сделано разработчиками Pivot с Wikipedia. Поработав с ней могу с уверенностью сказать - такой удобной энциклопедии мир пока не видел. Ниже находится ещё один видеоролик: на сей раз разработчики Pivot сами пытаются объяснить, что же они сделали и зачем это нужно. Про Wikipedia там тоже кое-что есть.
Отдельно хочется заметить, что, несмотря на кажущуюся сложность всей этой технологии, "бэк-энд" у неё довольно простой. Для создания коллекций не требуется даже особых “программерских” навыков. Коллекции состоят из двух частей: непосредственно элементов, описанных в XML, и иллюстраций в формате Deep Zoom.
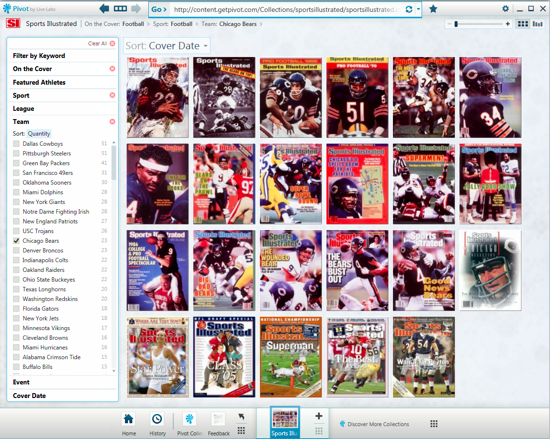
Существуют три основных типа коллекций. Их разница заключается в ограничении на максимальной размер и в способности возвращать результаты произвольных пользовательских запросов. Наиболее простые коллекции - статические. Например, обложки журнала Sports Illustrated. Искать по ним, используя произвольные запросы, нельзя, но можно сортировать, работая с атрибутами и ключевыми словами. К примеру, отбирать все обложки, на которых изображены игроки футбольной команды Chicago Bears.
Динамические коллекции прямо противоположны статическим и здесь пример - Wikipedia. В таких коллекциях XML генерируется автоматически, есть поддержка пользовательских запросов: информация динамически подгружается и обрабатывается с внешнего источника.
Наконец, третий тип коллекций - это связанные коллекции. Например, коллекция лучших фильмов от All Movie Guide состоит из отдельных, статических, но связанных между собой коллекций актеров и актрис. Соответственно, между ними можно свободно перемещаться.
Для просмотра коллекций необходимо использовать особый браузер, который так и называется - Pivot. На самом деле, это такой доработанный IE 8, поскольку он умеет спокойно открывать и обычные сайты. Возможно когда-нибудь, если мои прогнозы в отношении кнопки “Get in Pivot” сбудутся, функционал этого отдельного браузера будет перемещен в настоящий Internet Explorer, но пока приходится довольствоваться дополнительным приложением.
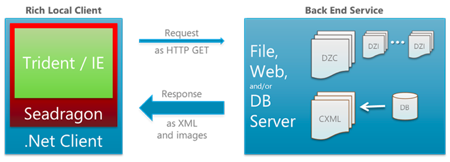
На картинке ниже вы видите архитектуру Pivot. Ничего сверхъестественного: набор файлов на сервере и локальный клиент, который знает, как их отображать в зависимости от того, зашёл ли пользователь на обычный сайт или обращается к коллекции.
А теперь вопрос к читателям: как вам кажется, этот новый способ представления информации в Интернете имеет шансы выжить, или он навсегда останется в стенах Microsoft Labs как это случилось с другими проектами (например, Thumbtack)? Чтобы ваш ответ был более осмысленным - вот обещанный код доступа к Pivot: 42A7 A3A3 5292 EDDF. Повторяю: использовать его смогут только первые 9 человек. Остальные могут запросить персональную копию на сайте Pivot или поискать в Google.
В завершение - про системные требования, так как есть большая вероятность, что код вам и не понадобится. Необходимо иметь, по меньшей мере, Windows Vista, а в идеале Windows 7 с включенным интерфейсом Aero (Windows XP не поддерживается в принципе), процессор не ниже 2 ГГц, 2 Гб “оперативки” и полноценную видеокарту с 256 Мб собственной памяти. И самое главное: работает Pivot только на английских версиях Windows с американским форматом отображения даты и времени. К этому также необходим .NET Framework 3.5 SP1 и Internet Explorer 8. Таковы ограничения “технического превью” Microsoft Pivot.
778 Прочтений • [Microsoft Pivot: новое в визуализации веб-контента] [24.04.2012] [Комментариев: 0]













 Vova
Vova